 |
 |
 |
 |
 |
 |
 |
  |
  |
 |
ele1-2-495: Estimation of the Low Voltage Electrical Line Length in Rural Towns
 |  |  |  |  |  |  |  |
Description
| Name: ele1-2-495 Type: Real-world problem |
| Number of input variables: 2 Number of examples: 495 |
| Domain of the input variable 1: [1, 320] Domain of the input variable 2: [60, 1673.329956] Range of the output variable: [80, 7675] |
Sometimes, there is a need to measure the amount of electricity lines that an electric company owns. This measurement may be useful for several aspects such us the estimation of the maintenance costs of the network, which was the main goal of the problem presented here in Spain. High and medium voltage lines can be easily measured, but low voltage line is contained in cities and villages, and it would be very expensive to measure it. This kind of line used to be very convoluted and, in some cases, one company may serve more than 10,000 small nuclei. An indirect method for determining the length of line is needed.
The problem involves finding a model that relates the total length of low voltage line installed in a rural town with the number of inhabitants in the town and themean of the distances from the center of the town to the three furthest clients in it. This model will be used to estimate the total length of line being maintained.
In this problem, it would be preferable that the solutions obtained verify the following requirement: they have not only to be numerically accurate in the problem-solving, but must be able to explain how a specific value is computed for a certain village. That is, it is interesting that these solutions are interpretable by human beings to some degree. Therefore, the use of gray-box techniques such as fuzzy modeling is recommended.
In this problem, five or seven linguistic terms are usually considered for each variable in linguistic fuzzy modeling.
Data Sets
The original data set of 495 examples has been randomly divided into 5 different subsets of 99 examples each of them. Joining 4 of these subsets in a training data set and keeping the fifth subset as test data set it is possible to build 5 different partitions of the original data set at 80%-20%, i.e., a 5-fold cross-validation. Some papers only consider a data set partition, in this case, the first partition is used.
| Training (80%, 396 examples) | Test (20%, 99 examples) |
| ele1-2-495-1.tra | ele1-2-495-1.tst |
| ele1-2-495-2.tra | ele1-2-495-2.tst |
| ele1-2-495-3.tra | ele1-2-495-3.tst |
| ele1-2-495-4.tra | ele1-2-495-4.tst |
| ele1-2-495-5.tra | ele1-2-495-5.tst |
You can also download the whole data set here.
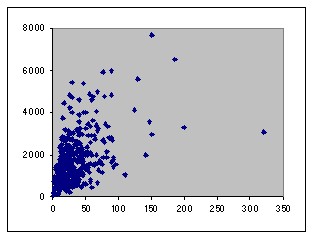
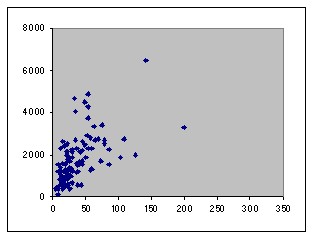
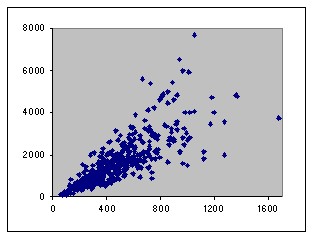
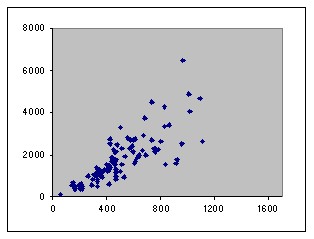
The existing dependency of the two input variables with the output variable in the first training and test data sets is shown below.
| (X1,Y) in ele1-2-495-1.tra | (X1,Y) in ele1-2-495-1.tst |
 |  |
| (X2,Y) in ele1-2-495-1.tra | (X2,Y) in ele1-2-495-1.tst |
 |  |
Results
| Non-Fuzzy Modeling Techniques | |||||||
| Reference | Method | Type | #Rules | #Labels | Training | Test | Experiment type |
| [CHS99] | Linear | Regression | 7 nodes | 2 par. | 287,775 | 209,656 | 1 partition |
| [CHS99] | Exponential | Regression | 7 nodes | 2 par. | 232,743 | 197,004 | 1 partition |
| [CHS99] | 2nd-order polynomial | Regression | 25 nodes | 6 par. | 235,948 | 203,232 | 1 partition |
| [CHS99] | 3rd-order polynomial | Regression | 49 nodes | 10 par. | 235,934 | 202,991 | 1 partition |
| [CHS99] | 3 layer perceptron 2-25-1 | Neural Network | -- | 102 par. | 169,399 | 167,092 | 1 partition |
| [San00] | GA-P | GA-P | 20 nodes | 3 par. | 183,693 | 159,837 | 1 partition |
| [San00] | Interval GA-P | GA-P | 16 nodes | 3 par. | 192,908 | 158,737 | 1 partition |
| Linguistic Fuzzy Modeling: Learning only the Rule Base (highest interpretability) | |||||||
| Reference | Method | #Rules | #Labels | Training | Test | Experiment type | |
| [CCH02] | Wang & Mendel | 22 | 21 | 211,733 | 236,770 | 5-fold CV | |
| [CCH02] | COR | 30 | 21 | 171,659 | 203,050 | 5-fold CV | |
| Linguistic Fuzzy Modeling: Learning/Tuning also the Data Base | |||||||||||
| Reference | Method | Learning | Tuning | MF param. | Granularity | Context | #Rules | #Labels | Training | Test | Exp. type |
| [CHS99] | MOGUL-D | — |  | | — | — | 19 | 21 | 150,559 | 166,669 | 1 partition |
| [CHV01] | Gr+MF | | — | | | — | 25 | 21 | 149,832 | 152,724 | 1 partition |
| [CHMV01] | Gr+MF+Context | | — | | | | 19 | 24 | 163,249 | 147,062 | 1 partition |
| [CHMV01] | Gr+MF+Context | | — | | | | 7 | 18 | 171,137 | 155,589 | 1 partition |
| Linguistic Fuzzy Modeling: Extending the Model Structure | ||||||||
| Reference | Method | 2 consequents | Hierarchical KB | #Rules | #Labels | Training | Test | Experiment type |
| [CH00] | ALM | | — | 13 | 15 | 178,571 | 180,848 | 1 partition |
| [CH00] | ALM | | — | 35 | 21 | 154,470 | 167,061 | 1 partition |
| [CHZ01] | HSLR | — | | 12 | 24 | 178,950 | 167,318 | 1 partition |
| Precise Fuzzy Modeling: TSK-type FRBSs | ||||||
| Reference | Method | #Rules | #Labels | Training | Test | Experiment type |
| [CHS99] | MOGUL-TSK | 20 | 21 | 162,609 | 148,514 | 1 partition |
References
The application was originally proposed in:| [CHS99] | O. Cordón, F. Herrera, L. Sánchez, Solving electrical distribution problems using hybrid evolutionary data analysis techniques, Applied Intelligence 10 (1999) 5-24. |
| [San00] | L. Sánchez, Interval-valued GA-P algorithms, IEEE Transactions on Evolutionary Computation 4:1 (2000) 64-72. |
| [CH00] | O. Cordón, F. Herrera, A proposal for improving the accuracy of linguistic modeling, IEEE Transactions on Fuzzy Systems 8:3 (2000) 335-344. |
| [CHV01] | O. Cordón, F. Herrera, P. Villar, Generating the knowledge base of a fuzzy rule-based system by the genetic learning of the data base, IEEE Transactions on Fuzzy Systems 9:4 (2001) 667-674. |
| [CHMV01] | O. Cordón, F. Herrera, L. Magdalena, P. Villar, A genetic learning process for the scaling factors, granularity and contexts of the fuzzy rule-based system data base, Information Sciences 136:1-4 (2001) 85-107. |
| [CHZ01] | O. Cordón, F. Herrera, I. Zwir, Linguistic modeling by hierarchical systems of linguistic rules, IEEE Transactions on Fuzzy Systems, 2001. To appear. |
| [CCH02] | J. Casillas, O. Cordón, F. Herrera, COR: A methodology to improve ad hoc data-driven linguistic rule learning methods by inducing cooperation among rules, IEEE Transactions on Systems, Man, and Cybernetics—Part B: Cybernetics 32:4 (2002) 526-537. |
Fuzzy Modeling Library (FMLib)
© Jorge Casillas